Przy projektowaniu stron internetowych na WordPressie, często spotykamy się z wyzwaniem przenoszenia krótkich słów, pojedynczych liter lub symboli (takich jak cudzysłowy) na nową linię. To może zakłócić estetykę i czytelność tekstu, tworząc niepożądane „sieroty”. W tym wpisie pokażę, jak zmodyfikować funkcję PHP, aby zapobiegać temu problemowi, co zdecydowanie poprawi wygląd Twoich postów i stron.
Zrozumienie i rozwiązanie problemu "sierot"
„Sieroty” to pojęcie typograficzne odnoszące się do pojedynczych słów, krótkich fraz lub symboli, które zostają samodzielnie przeniesione na nową linię tekstu, zwykle na końcu akapitu. Te osamotnione fragmenty tekstu nie tylko zakłócają wizualną harmonię strony, ale również mogą utrudniać płynne czytanie, skupiając uwagę czytelnika na nieestetycznym rozmieszczeniu tekstu.
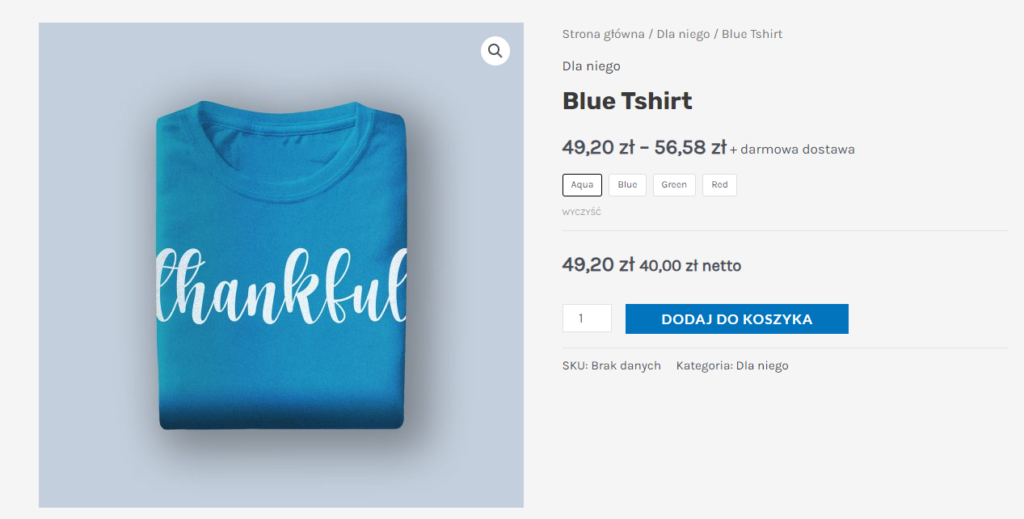
Poniżej prezentuję przykład pojedynczej litery „z” na końcu linii. Mała rzecz, ale w zauważalny sposób psująca wygląd całego akapitu:

Aby uniknąć takiego stanu rzeczy, możemy zaimplementować prostą modyfikację która pomoże nam kontrolować, jak tekst jest łamany.
Poniżej zamieszczam fragment kodu (snippet) PHP, który możemy dodać do naszego projektu WordPress. Dwa najprostsze moim zdaniem sposoby na dodawanie snippetów zawarłem w oddzielnym artykule.
function ezpage_prevent_orphans($content) {
return preg_replace_callback('/>[\s\S]*?</', function($matches) {
return preg_replace(
'/(\s)([a-zA-ZąćęłńóśżźĄĆĘŁŃÓŚŻŹ0-9,.!?()\'"]{1,2})(\s)/u',
'$1$2 ',
$matches[0]
);
}, $content);
}
add_filter('the_content', 'ezpage_prevent_orphans');Jak działa funkcja?
Funkcja ezpage_prevent_orphans wykorzystuje wyrażenia regularne do wyszukiwania miejsc w tekście, które mogą tworzyć nasze „sieroty”. Następnie, zastępuje standardową spację pomiędzy ostatnimi słowami akapitu a znakiem non-breaking space ( ). Po kolei, dla zainteresowanych:
- Zastosowanie wyrażeń regularnych: Funkcja zaczyna od zastosowania funkcji
preg_replace_callback, która przeszukuje całą treść strony lub posta w poszukiwaniu fragmentów tekstu otoczonych tagami HTML. Jest to istotne, aby nasze modyfikacje dotyczyły tylko widocznego tekstu, a nie kodu HTML. - Wyznaczanie miejsc do modyfikacji: Dla każdego znalezionego fragmentu, funkcja uruchamia inną funkcję
preg_replace, której celem jest identyfikacja miejsc, gdzie pojedyncze słowa, krótkie frazy lub symbole mogą zostać osamotnione na końcu linii. To dotyczy szczególnie krótkich wyrazów (jedno- lub dwuliterowych), cyfr, znaków interpunkcyjnych oraz cudzysłowów. - Zamiana spacji na non-breaking space: Kiedy potencjalna „sierota” zostaje zidentyfikowana, funkcja zastępuje standardową spację przed nią na non-breaking space (
). Non-breaking space to specjalny znak HTML, który zapobiega przenoszeniu elementu poprzedzającego go na nową linię. Dzięki temu, ostatnie słowa w linii nie zostaną oddzielone od reszty tekstu. - Automatyczne zastosowanie na całej stronie: Po przetworzeniu fragmentów tekstu, zmodyfikowana treść jest zwracana i wyświetlana na stronie. Funkcja jest wywoływana automatycznie dla każdego tekstu przechodzącego przez filtr
the_contentw WordPressie, co oznacza, że każdy post, strona czy inny typ treści będą automatycznie korzystać z tej modyfikacji.